
Momentum Contrast(MoCo)
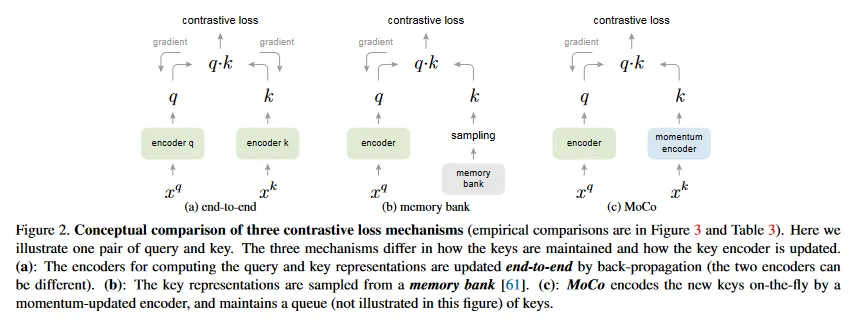
간단히 말해 Momentum Contrast(MoCo)는 기존의 Memory Bank를 사용하는 Contrastive Learning 방식에 Queue를 이용한 Dictionary를 사용하고 Key encoder를 업데이트하는데 Momentum을 사용하는 방식이다. MoCo의 Contrastivei Learning loss는 임의의 것을 사용 가능하지만 논문의 저자들은 InfoNCE 형식(참고 자료)의 loss를 사용했다.
Dictionary as a Queue
MoCo는 우선 Queue 형식의 Dictionary를 사용하여 mini-batch 단위로 인코딩된 key를 관리한다. 현재 mini-batch의 샘플들이 encoder를 통해 key로 인코딩된 후에 dictionary에 enqueue 되고, 오래된 key는 dequeue 되어 dictionary는 동적으로 관리된다. 이로 인해 dictionary는 mini-batch의 크기와 독립적이며, 일반적인 mini-batch의 크기보다 훨씬 커질 수 있다.
mini-batch의 key들이 queue에 순차적으로 관리되기 때문에 직전 mini-batch에서 인코딩된 key를 재사용하는 것이 가능하며, 가장 오래 전에 인코딩된 key를 제거하는 것이 최신 인코딩된 key와 일관성이 떨어질 수 있기 때문에, 보다 일관성 있는 표현을 학습할 수 있게 된다.
추가로 MoCo에서는 Memory Bank와 달리 Memory Bank내의 key을 무작위로 샘플링하지 않고 Queue 내의 모든 key와 입력 Query를 비교하여 loss를 계산하는데, 이 추가 계산 비용은 논문 저자들에 따르면 관리 가능한 수준이라고 한다.
Momentum Update
기본적으로 Memory Bank 내에 존재하는 샘플들에 대해 역전파를 수행하는 것이 까다롭기 때문에 Memory Bank에서는 query와 key를 인코딩하는데 단일 encoder를 사용한다. 이와 달리 MoCo에서는 query와 key를 위한 2개의 encoder 를 사용하는데, 다음과 같은 방식으로 Dictionary 내의 샘플에 gradient를 업데이트한다.
우선 입력 query를 인코딩하는 Query 인코더는 일반적인 encoder로 각 mini-batch 마다 역전파를 통해 파라미터가 업데이트 된다. 반면 mini-batch 마다 Dictionary queue에 넣을 key를 인코딩하는 Key 인코더는 Query 인코더를 복사해서 사용하되, Momentum을 사용하여 업데이트 속도를 조절한다.
여기서 는 의 파라미터이고 는 의 파라미터이고, 은 momentum 계수이다. 이 식을 통해 key 인코더는 본질적으로 query 인코더와 동일하지만, 업데이트 속도를 완만하게 하여 Key representation의 일관성을 유지한다.
저자들은 query 인코더의 파라미터를 key 인코더에 그대로 복사하면 Key representation의 일관성이 빠르게 줄어들어서 좋지 않은 결과를 발생시키고, 느리게 진화하는 Key 인코더가 Queue를 활용하는데 핵심이라고 주장했다.
Shuffling Batch Normalization
저자들이 MoCo를 이용하여 실험을 진행할 때 Batch Normalization(BN)이 좋은 representation을 학습하는데 방해하는 것을 발견했고, 이것이 BN에 의해 발생하는 batch 내부의 커뮤니케이션으로 인해 샘플 사이의 정보 누출 때문일 것으로 추측했다. 결과적으로 모델은 ‘cheat’를 통해 쉽게 낮은 loss 해를 찾는다.
이를 방지하기 위해 저자들은 GPU에 mini-batch를 분배하기 전에 shuffling BN을 사용하고, 인코딩 후에 다시 원래로 되돌리는 작업을 수행했다. 이 방법은 cheating 이슈를 다루고 BN에서 이점을 얻게 했다고 한다.
Sample Code
실제 여러 대의 GPU 환경에서 Main Node에서 mini-batch와 dictionary를 분배하고, 각 GPU에서 업데이트된 파라미터와 dictionary를 다시 Main Node에 보내서 동기화하고 그걸 다시 각 GPU에 분배하는 것은 복잡하므로 논문에 나온 아래의 pseudo-code로 MoCo 샘플 코드를 대체한다.
아래에서 q와 x는 동일한 입력 각각 증기시킨 뒤 query 인코더와 key 인코더를 통과시켜 구하고(이때 k는 역전파를 무시하기 위해 detach()를 함), 해당 q, k는 동일한 입력이었으므로 이 둘을 곱해 positive를 얻고, q를 기존의 queue와 곱해 negative를 구하는 식으로 구성된다.
loss를 구한 후에 역전파를 하여 query 인코더를 업데이트 한 후에 momentum을 이용하여 key 인코더를 업데이트하고, mini-batch의 마지막에 새로 인코딩된 key를 queue에 추가하고 가장 오래된 key를 queue에서 제거한다.
# f_q, f_k: encoder networks for query and key
# queue: dictionary as a queue of K keys (CxK)
# m: momentum
# t: temperature
f_k.params = f_q.params # initialize
for x in loader: # load a minibatch x with N samples
x_q = aug(x) # a randomly augmented version
x_k = aug(x) # another randomly augmented version
q = f_q.forward(x_q) # queries: NxC
k = f_k.forward(x_k) # keys: NxC
k = k.detach() # no gradient to keys
# positive logits: Nx1
l_pos = bmm(q.view(N,1,C), k.view(N,C,1))
# negative logits: NxK
l_neg = mm(q.view(N,C), queue.view(C,K))
# logits: Nx(1+K)
logits = cat([l_pos, l_neg], dim=1)
# contrastive loss, Eqn.(1)
labels = zeros(N) # positives are the 0-th
loss = CrossEntropyLoss(logits/t, labels)
# SGD update: query network
loss.backward()
update(f_q.params)
# momentum update: key network
f_k.params = m*f_k.params+(1-m)*f_q.params
# update dictionary
enqueue(queue, k) # enqueue the current minibatch
dequeue(queue) # dequeue the earliest minibatch
Python
복사
