
CLIP(Contrastive Language-Image Pre-training)
CLIP은 text-image 쌍에 대해 Contrastive learning을 사용하여 multi-modal embedding을 학습하는 방법이다.
이에 대한 아이디어는 다음과 같다. 를 -번째 이미지라 하고 를 매칭하는 텍스트라 하자. 이미지와 연관된 정확한 단어를 예측하려고 하는 대신 미니배치 내의 어떤 다른 텍스트 에 대해 가 와 비해 올바른 텍스트일 가능성이 더 높은지 확인한다. 유사하게 모델은 이미지 가 보다 주어진 텍스트 와 일치할 가능성이 더 높은지 확인한다.
더 정확하게 를 이미지의 임베딩이라 하고 를 텍스트의 임베딩, 를 이미지 임베딩의 unit-norm, 를 텍스트 임베딩의 unit-norm이라 하자. pairwise logit의 벡터(유사도 점수)를 다음처럼 정의한다. (실제에서는 cosine 유사도를 사용한다.)
이제 두 임베딩 함수 와 의 파라미터를 훈련하여 다음의 손실을 최소화할 수 있다. 크기 의 미니배치에 대해 평균화한다.
여기서 는 cross entropy 손실이고 는 라벨 의 원-핫 인코딩이다. 는 행에 대한 cross-entropy로 번째 이미지에 대한 텍스트의 매칭을 나타내며, 는 열에 대한 cross-entropy 손실로 번째 텍스트에 대한 이미지의 매칭을 나타낸다. 아래 그림 참조.
실제로는 학습된 temperature 파라미터로 임베딩의 normalized 크기가 조정되며 이것은 softmax의 sharpness를 제어한다.
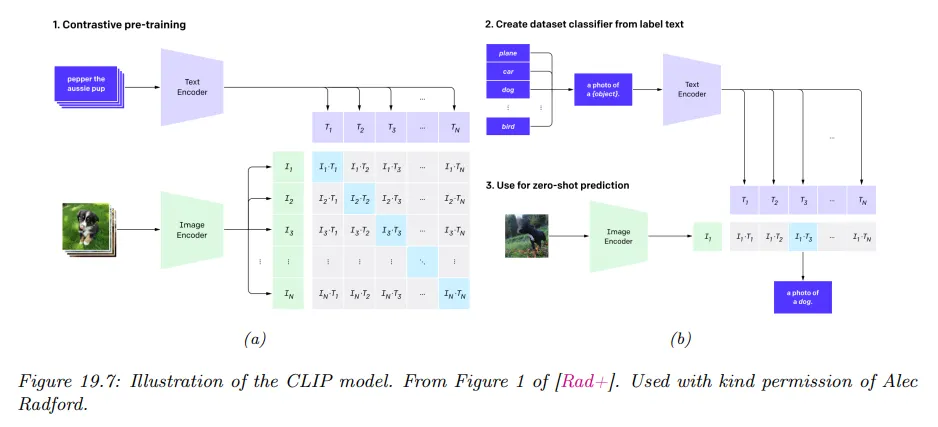
모델이 훈련된 후에는 다음과 같이 이미지 의 zero-shot 분류에 사용할 수 있다.
1.
주어진 데이터셋에 대해 개 가능한 클래스 라벨의 각각을 웹에서 나타날 수 있는 text string 로 변환한다. 예컨대 ‘dog’은 ‘a photo of a dog’이 된다.
2.
normalized 임베딩 와 을 계산한다.
3.
다음의 softmax 확률을 계산한다.
이 접근은 놀랍게도 특정 라벨이 지정된 데이터셋에 대해 명시적으로 학습하지 않고도 이미지넷 분류 같은 표준 supervised 학습과 동일한 성능을 발휘할 수 있었다. 물론 이미지넷의 이미지는 웹에서 가져온 것이고 텍스트 기반 웹 검색을 통해 찾은 것이기 때문에 모델은 이전에 유사한 데이터를 본 적이 있다. 그럼에도 불구하고 새로운 작업에 대한 일반화와 분포 변화에 대한 견고성은 매우 인상적이었다.
Sample Code
Model
이미지와 텍스트에 대한 Embedding을 수행하는 모델을 정의한다. SimCLR과 마찬가지로 consine 유사도를 계산에 사용하기 위해 모델의 출력을 정규화한다.
class ImageEmbeddingModel(nn.Module):
def __init__(self, embedding_dim):
super(ImageEmbeddingModel, self).__init__()
self.base_model = models.resnet18(pretrained=True)
in_features = self.base_model.fc.in_features
self.base_model.fc = nn.Linear(in_features, embedding_dim)
def forward(self, x):
return F.normalize(self.base_model(x), dim=1) # 코사인 유사도 계산에 사용하기 위해 임베딩 벡터를 정규화
class TextEmbeddingModel(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(TextEmbeddingModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.transformer = nn.Transformer(embedding_dim, nhead=8, num_encoder_layers=3)
self.fc = nn.Linear(embedding_dim, embedding_dim)
def forward(self, x):
x = self.embedding(x)
x = self.transformer(x, x)
x = x.mean(dim=1)
return F.normalize(self.fc(x), dim=1) # 코사인 유사도 계산에 사용하기 위해 임베딩 벡터를 정규화
Python
복사
Objective
CLIP의 loss 식을 따라 다음과 같이 구현한다.
여기서 image_features, text_features는 모두 모델을 통과해서 정규화된 데이터이다. 그 둘을 곱해 유사도 행렬을 구한다. image에 대한 text 유사도와 text에 대한 image 유사도는 결과가 같고 서로 전치인 행렬이다.
데이터가 동일한 index에 대해 쌍으로 맞춰져 있으므로 정답은 대각 성분이 된다. 따라서 정답 labels는 batch_size 크기에 대해 1씩 증가하는 벡터가 된다.
Pytorch의 F.cross_entropy()는 주어진 행렬에 대해 log softmax를 수행한 후, 행별로 주어진 정답 labels의 인덱스에 해당하는 항목만 합한 뒤 평균을 취하는 함수이다. 이것은 (softmax를 취한 후에) 에 대해 labels를 로 받고, 행렬의 각 행을 로 받은 다음, labels의 index에 해당하는 부분만 로 설정하고 나머지는 으로 설정한 것과 같다. 그렇게 행별로 1개의 값만 남겨서 음의 로그를 취한 뒤 모든 행의 값을 더하고 평균낸다.
def clip_loss(image_features, text_features, temperature=0.5):
# 유사도 행렬 계산 (코사인 유사도)
logits_per_image = torch.matmul(image_features, text_features.t()) / temperature
logits_per_text = logits_per_image.t()
# 정답 레이블 생성
batch_size = image_features.shape[0]
labels = torch.arange(batch_size, device=image_features.device)
# Cross-Entropy 손실 계산
loss_i = F.cross_entropy(logits_per_image, labels)
loss_t = F.cross_entropy(logits_per_text, labels)
# 최종 손실 계산
loss = (loss_i + loss_t) / 2.0
return loss
Python
복사
Train
image-text 쌍에 대해 이미지와 텍스트를 각각 image embedding 모델과 text embedding 모델에 넣어 embedding 한 후에 CLIP loss 함수를 이용해서 image-text 쌍별 유사도와 손실을 계산한 다음 역전파 하여 embedding을 업데이트 한다.
class SampleDataset(Dataset):
def __init__(self, num_samples, vocab_size, image_size):
self.num_samples = num_samples
self.vocab_size = vocab_size
self.image_size = image_size
self.transform = transforms.Compose([
transforms.Resize((image_size, image_size)),
transforms.ToTensor()
])
def __len__(self):
return self.num_samples
def __getitem__(self, idx):
image = torch.randn(3, self.image_size, self.image_size)
text = torch.randint(0, self.vocab_size, (10,))
return image, text
# 샘플 데이터셋 생성
num_samples = 1000
vocab_size = 10000
image_size = 224
batch_size = 32
dataset = SampleDataset(num_samples, vocab_size, image_size)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 하이퍼파라미터 설정
embedding_dim = 256
learning_rate = 3e-4
num_epochs = 10
temperature = 0.5
# 모델 초기화
image_model = ImageEmbeddingModel(embedding_dim).cuda()
text_model = TextEmbeddingModel(vocab_size, embedding_dim).cuda()
# 최적화 설정
optimizer = optim.Adam(list(image_model.parameters()) + list(text_model.parameters()), lr=learning_rate)
# 학습 루프
for epoch in range(num_epochs):
total_loss = 0
for images, texts in dataloader:
images = images.cuda()
texts = texts.cuda()
# 모델을 통해 임베딩 계산
image_features = image_model(images)
text_features = text_model(texts)
# 손실 계산
loss = clip_loss(image_features, text_features, temperature)
# 역전파 및 최적화
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(dataloader)
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {avg_loss:.4f}")
print("Training completed.")
Python
복사
