
Masked Auto-Encoder(MAE)
Masked Auto-Encoder는 입력을 encoder를 통해 저차원 latent space로 투영했다가 decoder를 통해 해당 latent space에서 입력을 복원하는 구조를 갖는 전통적인 Autoencdoer의 변종으로 입력에 Mask를 씌운 후에 Mask된 부분을 픽셀 레벨로 복원하는 모델이다.
개념 자체는 Autoencoder를 따르기 때문에 간단한데, encoder에 ViT를 사용하고, decoder에는 Lightweight Transformer decoder를 사용하여 전통적인 Autoencoder와 달리 비대칭이라는 특징이 있다. 전체적인 아키텍쳐가 간단해서 모델을 확장하기 용이하다는 장점이 있다.
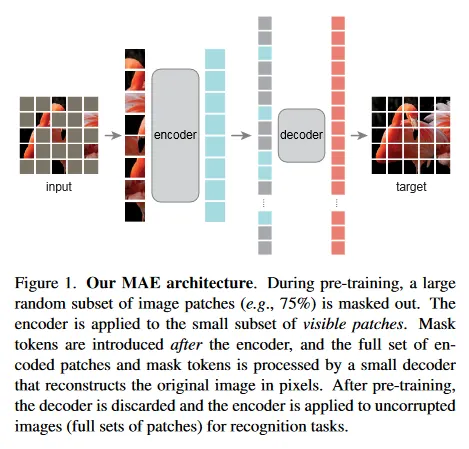
Masking

입력을 Masking 할 때는 ViT처럼 겹치지 않는 Grid로 Patch를 분할한 후, 무작위로 전체 Patch의 (무려) 75%를 Masking하여 사용한다. Encoder에서는 Masking 되지 않은 나머지에 대해서만 positional embedding을 추가한 다음 ViT를 통해 latent space로 embedding한다.
Decoder에서는 encoder의 embedding 데이터와 Masking 된 patch를 모두 입력 받고 전체에 대해 positional embedding을 추가한 다음 원본 이미지를 복원한다. Transformer의 decoder를 사용하지만 auto-regressive하게 결과를 출력하지 않고 한 번에 결과를 출력한다.
마지막으로 복원된 결과 픽셀과 원본 입력의 픽셀 사이의 MSE(mean squared error)를 loss로 사용하여 파라미터를 학습한다.
더 자세한 내용은 참고의 논문 페이지 참조.
Sample Code
아래는 encoder에 ViT를 사용하고 decoder에 Lightweight Transformer decoder를 사용하는 예시 코드이다.
encoder에서 입력을 patch로 만든 후에 visible_patch만 encoding을 수행한다. decoder에서는 encoder의 출력과 mask 된 입력을 함께 사용하여 결과를 출력한다.
import torch
import torch.nn as nn
from timm.models.vision_transformer import VisionTransformer
class MAE(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768, decoder_dim=512, mask_ratio=0.75):
super(MAE, self).__init__()
# ViT Encoder
self.encoder = VisionTransformer(img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
# Decoder: Lightweight Transformer Decoder
self.decoder = nn.Transformer(d_model=decoder_dim, nhead=8, num_encoder_layers=6, num_decoder_layers=6)
# Masking Ratio
self.mask_ratio = mask_ratio
def forward(self, x):
# Split the image into patches
B, C, H, W = x.shape
patches = self.encoder.patch_embed(x) # Convert image into patches
# Mask some of the patches randomly
num_patches = patches.shape[1]
num_mask = int(self.mask_ratio * num_patches)
mask = torch.rand(B, num_patches).argsort(dim=-1)[:, :num_mask]
# Encode only visible patches
visible_patches = patches.clone()
visible_patches[:, mask] = 0 # Set masked patches to zero
latent = self.encoder(visible_patches)
# Prepare decoder input (concatenate mask tokens)
mask_tokens = torch.zeros_like(latent)
mask_tokens[:, mask] = self.encoder.pos_embed[:, mask] # Add positional embedding for masked tokens
decoder_input = torch.cat([latent, mask_tokens], dim=1)
# Decode to reconstruct the image
reconstructed_patches = self.decoder(decoder_input, decoder_input)
return reconstructed_patches
# Example instantiation
model = MAE(img_size=224, patch_size=16, embed_dim=768, decoder_dim=512, mask_ratio=0.75)
Python
복사
학습 예시 코드. 모델의 결과를 MSE loss를 이용해서 loss를 계산하고 파라미터를 업데이트한다.
import torch.optim as optim
# Loss function (MSE)
loss_fn = nn.MSELoss()
# Optimizer
optimizer = optim.AdamW(model.parameters(), lr=1e-4)
# Dummy input (batch size 8, 3 channels, 224x224 image)
dummy_input = torch.randn(8, 3, 224, 224)
# Training loop
for epoch in range(10): # Train for 10 epochs
model.train()
# Forward pass
reconstructed_patches = model(dummy_input)
# Compute loss (between reconstructed patches and original input patches)
original_patches = model.encoder.patch_embed(dummy_input) # Original patches for comparison
loss = loss_fn(reconstructed_patches, original_patches)
# Backward pass and optimization
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}, Loss: {loss.item()}')
Python
복사
