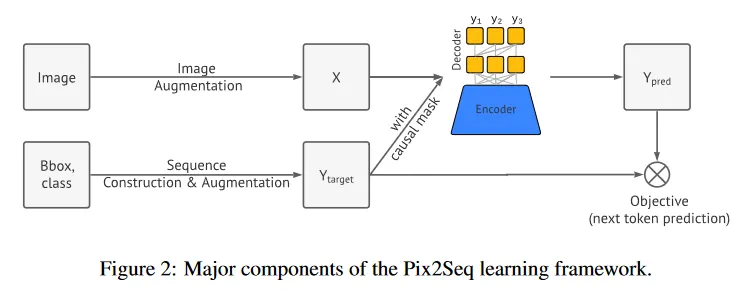
Pix2Seq
Pix2Seq는 object detection에 대한 vision task를 언어 모델링 task로 변환한 모델이다. 이것은 Transformer 아키텍쳐를 object detection 분야에 접목 시키기 위한 시도로 볼 수 있다. 이 모델은 ViT와 달리 Transformer에 넣기 위해 이미지를 patch로 나누는 작업은 하지 않는다.
기본적으로 Transformer의 Encoder-Decoder 구조를 활용하며, 원본 이미지를 Augmentation 하여 Transformer의 Encoder에 입력으로 넣어서 해당 이미지의 feature representation을 학습한다. 이 학습된 표현은 decoder에 입력으로 사용된다.
decoder에서는 이미지에서 detect 해야 하는 object에 대한 예측을 수행한다. 해당 예측은 object의 bounding box와 class id에 해당하는 의 5개의 token으로 수행된다. 즉 하나의 object를 detect 하기 위해 decoder는 5번 출력을 생성해야 한다. 원래의 transformer와 마찬가지로 생성된 출력은 다음 시퀀스의 입력으로 활용된다.
학습 이미지에서 object의 bounding box를 이루는 좌표는 실수값이기 때문에 이것을 이산화된 bin 형태로 만들어서 토큰으로 사용한다. 또한 원래의 transformer와 같이 EOS 토큰이 생성되면 detect 절차는 종료된다.
더 자세한 내용은 참고의 논문 페이지 참조.