
Background
I-JEPA의 아키텍쳐를 이해하기 위해 알아야 하는 아키텍쳐 구조가 있다. 아래 그림 참조.
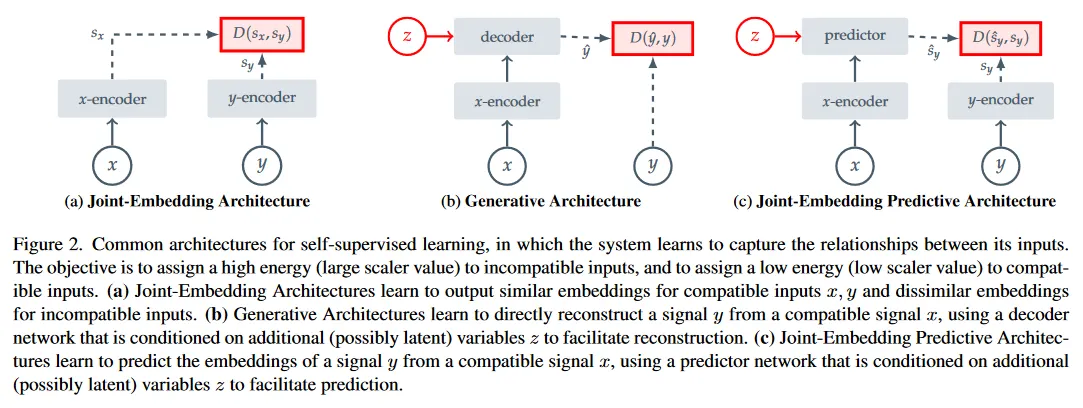
Joint-Embedding Architectures.
논문에서 지칭하는 Joint-Embedding Architecture는 2개의 입력을 각각 별도의 encoder에 통과시킨 후 원래의 입력이 유사했으면 가깝게, 원래 입력이 유사하지 않았으면 멀리 임베딩하는 구조를 갖는다. 이것은 positive pair를 가까이, negative pair를 멀리 떨어뜨리는 contrastive learning 방식과 유사하다.
Generative Architectures.
논문에서 지칭하는 Generative Architecture는 하나의 입력을 encoder에 통과시킨 후, encoding 된 데이터를 (latent 변수에 조건화 된) decoder를 통해 원하는 입력으로 복구 한다—오염된 입력을 원본으로 복구하는 것일 수 있음. 이것은 Autoencoder 류의 방법과 유사하다.
Joint-Embedding Predictive Architectures.
논문에서 지칭하는 Joint-Embedding Predictive Architecture는 위의 Joint-Embedding과 Generative Architecture를 합친 방법으로 두 입력을 각각 다른 encoder에 통과 시킨 후에, (latent 변수에 조건화 된) predictor가 다른 네트워크의 출력을 예측한다.
이 방법은 BYOL과 유사한데, JEPA는 loss를 pixel 공간에서 계산하지 않고 representation 공간에서 계산한다는 점에서 차이가 있다. 또 다른 차이는 Masking을 이용한 학습 방법인데 아래에서 설명.
Images with Joint-Embedding Predictive Architecture(I-JEPA)
JEPA는 Self-Supervised learning으로 Image의 Representation을 학습하고, Downstream Task로 transfer하는 목적을 갖는 모델이다. 이것은 Masking을 이용하여 학습한다는 점에서 MAE과 유사하고, 다른 네트워크를 통해 입력을 encoding한 다음 다른 네트워크의 출력을 예측하는 predictor가 존재한다는 점에서 BYOL과도 유사하다.
Context Encoder와 Target Encoder는 동일한 네트워크를 사용하지만 Context Encoder만 역전파를 통해 파라미터를 업데이트하고 Context Encoder의 파라미터를 Exponential Moving Average로 Target Encoder의 파라미터에 업데이트 한다. (이것도 BYOL과 유사)
한편 Predictor는 예측만 수행하므로 MLP 형태를 사용할 수 있는데, 논문의 저자들은 Context Encoder와 Target Encoder, Predictor 모두에 ViT를 기본으로 사용하고, 그것이 가장 성능이 좋았다고 함.
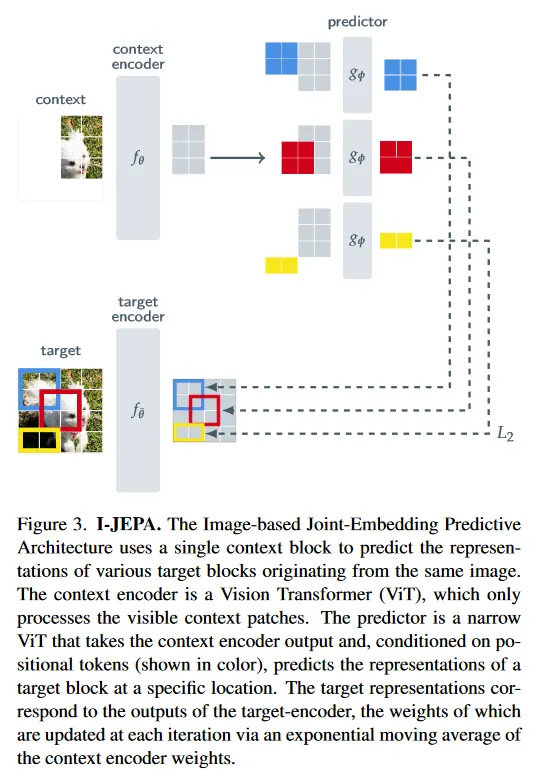
Target Encoder
우선 Target Encoder를 위해 원본 입력을 겹치지 않는 patch로 분할한 다음, 전체 패치를 target encoder에 통과시켜 patch-level representation을 얻는다.
그 다음 세로로 2배 긴 직사각형 크기(보다 정확히 (0.15, 0.2) 사이의 값을 취한 후 해당 값의 0.75를 width로 1.5를 height로 하는 직사각형)를 설정하고 해당 직사각형 내에 존재하는 patch를 모아 target block을 만든다. target block을 Target Encoder를 통과 시킨 결과로 만든다는 것에 주의.
이러한 target block은 개를 설정하는데 논문에서는 4개를 default로 사용 함.
Context Encoder
다음으로 Context Encoder를 위해 원본 이미지에 대해 정사각형 크기(보다 정확히 (0.85, 1.0) 사이의 크기)의 영역을 설정한 다음, 해당 영역 내에서 Target Block과 겹치는 부분을 masking 처리하여 context block을 얻는다.
이 context block을 context encoder에 통과시켜 patch-level representation을 얻는다. target block과 겹치는 부분을 masking 처리하여 context block을 얻는 것은 아래 이미지 참조.

Predictor
predictor에서는 context encoder를 통해 얻은 representation과 개의 target block에 해당하는 mask token(positional embedding이 추가된)을 입력으로 받고, 이것들을 이용하여 개의 target block의 representation에 대한 예측을 수행한다.
여기서 target block은 pixel 값이 아니라 representation이므로 predictor의 예측은 pixel 공간이 아니라 representation 공간에서 일어나게 된다. 이것은 JEPA가 pixel reconstruction 방법에 비해 빠르게 수렴하고 high semantic level의 representation을 학습하는데 도움이 된다고 한다.
predictor의 개의 예측과 정답 target block representation의 차이를 L2 거리로 계산하고 평균을 취하여 loss를 계산한다. 이렇게 구한 loss로 역전파를 통해 Context Encoder와 Predictor의 파라미터를 업데이트하고, Target Encoder의 파라미터는 Context Encoder의 파라미터에 대한 Exponential Moving Average로 업데이트 한다.
Transfer Learning
다른 representation을 학습하는 모델과 마찬가지로 I-JEPA는 이미지의 representation을 학습할 뿐, 직접 특정 task를 수행하지는 못하기 때문에, 각 task별로 transfer learning을 수행해야 한다. 이때 Context Encoder와 Predictor만 이용하고 (Target Encoder는 사실 Context Encoder와 동일하므로) Predictor 위에 해당 Task(예: classification, detection, segmentation)를 해결할 수 있는 network를 추가해서 fine-tuning하여 사용한다.
Sample Code
2개의 encoder와 1개의 predictor를 갖는 I-JEPA에 대한 개념적인 코드 샘플. 원본 소스 코드는 공식 홈페이지 소스 참조
Context Encoder와 Target Encoder는 ViT를 사용하는 것이 기본이지만, 다른 backbone을 사용하는 것도 가능하다. 다만 ViT를 사용하는 것이 모델을 더 간단하게 만들어서 확장성을 높일 뿐만 아니라 실제 성능도 ViT가 가장 좋았다고 함.
predictor는 context encoder의 출력에 positional embedding이 추가되는 mask_token을 이용하여 target encoder의 출력을 예측한다.
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision.models.vision_transformer import vit_b_16
# Vision Transformer 기반의 Context Encoder
class ContextEncoder(nn.Module):
def __init__(self, vit_model):
super(ContextEncoder, self).__init__()
self.vit = vit_model
def forward(self, x, mask=None):
# mask가 적용된 패치들을 처리
if mask is not None:
x = x * mask # mask 적용
return self.vit(x)
# Vision Transformer 기반의 Target Encoder (EMA로 업데이트)
class TargetEncoder(nn.Module):
def __init__(self, vit_model):
super(TargetEncoder, self).__init__()
self.vit = vit_model
def forward(self, x):
return self.vit(x)
# EMA 업데이트 함수
def update_moving_average(self, context_encoder, momentum=0.99):
for param_q, param_k in zip(context_encoder.parameters(), self.parameters()):
param_k.data = momentum * param_k.data + (1.0 - momentum) * param_q.data
# Predictor: M개의 mask token과 context embedding을 사용하여 마스킹된 패치 예측
class Predictor(nn.Module):
def __init__(self, embedding_dim, num_patches):
super(Predictor, self).__init__()
self.fc1 = nn.Linear(embedding_dim, embedding_dim)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(embedding_dim, embedding_dim)
# Positional embedding (num_patches는 패치 개수)
self.positional_embedding = nn.Parameter(torch.randn(num_patches, embedding_dim))
def forward(self, context_embedding, mask_tokens, patch_indices):
# M개의 mask token과 positional embedding을 사용하여 예측
outputs = []
for i, mask_token in enumerate(mask_tokens):
pos_emb = self.positional_embedding[patch_indices[i]]
mask_token_with_pos = mask_token + pos_emb # 위치 정보가 추가된 mask token
x = context_embedding + mask_token_with_pos
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
outputs.append(x)
# M개의 타겟 블록에 대해 예측된 임베딩을 반환
return torch.stack(outputs)
# JEPA 전체 모델
class JEPA(nn.Module):
def __init__(self, context_encoder, target_encoder, predictor):
super(JEPA, self).__init__()
self.context_encoder = context_encoder
self.target_encoder = target_encoder
self.predictor = predictor
def forward(self, context_block, target_block, mask_tokens, patch_indices):
# Context encoder 처리
context_embedding = self.context_encoder(context_block)
# Target encoder 처리 (타겟 블록 임베딩)
target_embedding = self.target_encoder(target_block)
# M개의 mask token에 대해 predictor가 예측 수행
predicted_embedding = self.predictor(context_embedding, mask_tokens, patch_indices)
return predicted_embedding, target_embedding
Python
복사
I-JEPA의 학습 샘플 코드
Context Encoder와 Predictor는 역전파를 통해 파라미터를 직접 업데이트하며, Target Encoder는 Context Encoder의 파라미터를 Exponential Moving Average를 이용해서 업데이트 한다. 이것은 BYOL에서 사용한 것과 유사하고 BYOL에서는 이것을 강화학습의 방법에서 차용했음.
# 하이퍼파라미터 설정
embedding_dim = 768 # ViT-B/16 embedding dimension
learning_rate = 1e-4
num_epochs = 10
num_patches = 16 # 예시로 이미지가 4x4로 분할된 경우
momentum = 0.99 # EMA 업데이트를 위한 모멘텀 값
M = 4 # 예시로 4개의 target block
# Vision Transformer 모델 생성 (사전 학습된 모델 사용)
vit_model = vit_b_16(pretrained=True)
# JEPA 모델 생성
context_encoder = ContextEncoder(vit_model)
target_encoder = TargetEncoder(vit_model) # target_encoder는 EMA 방식으로 업데이트됨
predictor = Predictor(embedding_dim, num_patches)
jepa_model = JEPA(context_encoder, target_encoder, predictor)
# 옵티마이저 설정
optimizer = optim.Adam(jepa_model.context_encoder.parameters(), lr=learning_rate) # context_encoder만 학습
loss_fn = nn.MSELoss()
# 학습 데이터 로딩 (샘플 이미지 데이터셋)
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 데이터셋 변환 및 로더 설정
transform = transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor()])
train_dataset = datasets.CIFAR10(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# 학습 루프
for epoch in range(num_epochs):
for i, (images, _) in enumerate(train_loader):
# 가상 컨텍스트 블록과 타겟 블록 생성 (간단하게 임의로 분리)
context_block = images[:, :, :112, :112] # 가상 컨텍스트 블록 (이미지의 일부분)
target_block = images[:, :, 112:, 112:] # 가상 타겟 블록 (나머지 이미지)
# M개의 mask token (학습 가능한 벡터)
mask_tokens = [torch.randn(context_block.size(0), embedding_dim) for _ in range(M)]
# 가상으로 M개의 패치 인덱스 생성 (예: 타겟 블록이 이미지에서 어떤 위치에 있는지)
patch_indices = [torch.randint(0, num_patches, (context_block.size(0),)) for _ in range(M)]
# 모델 포워드 패스 (M개의 mask token을 사용)
predicted_embedding, target_embedding = jepa_model(context_block, target_block, mask_tokens, patch_indices)
# 손실 계산 (L2 손실: MSE)
loss = loss_fn(predicted_embedding, target_embedding)
# 역전파 및 가중치 업데이트
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 매 스텝마다 EMA 업데이트
target_encoder.update_moving_average(context_encoder, momentum=momentum)
if i % 100 == 0:
print(f"Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss: {loss.item():.4f}")
Python
복사
