
Hiera(Hierarchical Vision Transformer)
Hiera는 ViT에 계층구조를 도입한 Encoder를 의미한다. 이것은 ViT에 계층구조를 도입한 이전의 supervised 모델인 MViTv2를 self-supervised 형식으로 개선한 모델이다. self-supervised 방식으로 학습하기 때문에 MViTv2에 있던 여러 component들 중 불필요한 것들(pooling attention, conv 등)을 모두 제거할 수 있었고 그 결과 동일한 또는 더 우수한 성능을 발휘하면서 더 가볍고 빠른 모델이 되었다.
self-supervised를 위해 Hiera는 MAE(Masked Autoencoder) 방식을 사용하여 모델을 학습한다. 이를 위해 masking 된 패치를 복원하는 별도의 decoder를 구현한다(코드 상에서 MaskedAutoencoderHiera 클래스가 이에 해당).
Hiera는 self-supervised로 이미지의 representation을 학습하는 것을 목적으로 하기 때문에, 모델을 학습 시킨 후에는 encoder 부분인 Hiera만 떼서 downstream task에 적용하는 식으로 활용한다.
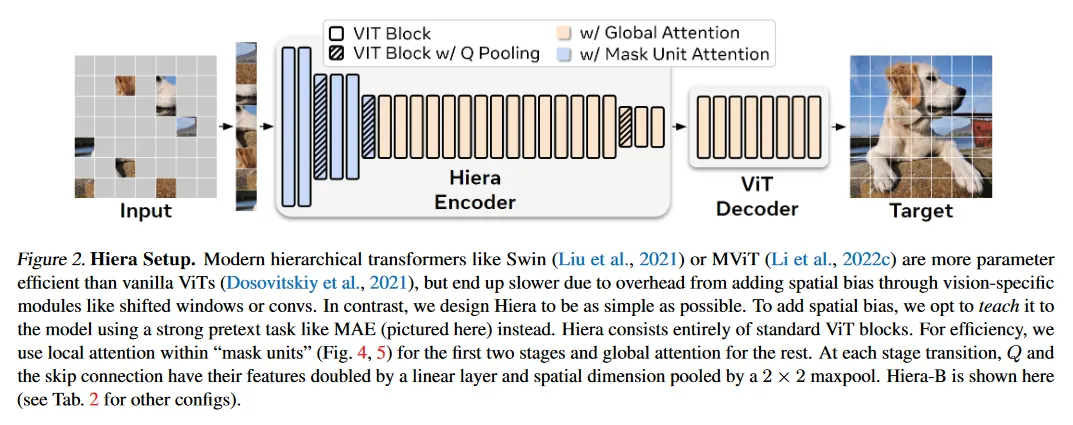
Training
본래의 ViT는 입력을 겹치지 않는 patch로 만들고 각 patch에 대해 나머지 모든 patch를 self-attention하여 MLP를 통과하는 것을 N번 수행한다. 전체 네트워크를 계층적(layer가 진행됨에 따라 이미지 크기를 줄이는 방식)으로 만들면, stage의 앞에서는 low-level feature를 학습하게 되고, stage의 뒤에서는 줄어든 이미지에서 자연스럽게 high-level feature를 학습하여 계산 효율성을 높일 수 있다.
ViT를 계층적으로 만들기 위해 MViTv2는 고정된 patch 크기를 만들고(이 patch들이 token으로 사용된다), stage가 진행됨에 따라 patch 수를 줄이는 방식으로 이것을 구현한다. 예컨대 입력 이미지가 224x224이고, patch 크기가 4x4였다면, 첫 stage에서 patch는 총 56x56개가 생성된다. 두 번째 stage에서 이미지 크기를 절반으로 줄이고 patch 크기를 유지하면 전체 patch는 총 28x28로 줄어들고, 이를 원하는 만큼 반복하여 patch 수를 줄인다.
Hiera는 MAE를 이용하여 모델을 학습 시키기 때문에 추가로 mask unit를 사용하는데, mask unit도 patch처럼 크기를 고정하여 처리한다. 예컨대 mask unit은 32x32 크기라면 첫 stage에서 총 8x8개의 patch를 masking 처리된다. 두 번째 stage에서 이미지 크기가 절반으로 줄었기 때문에 patch의 갯수가 절반으로 줄어들게 되고, masking 되는 patch의 수도 4x4로 줄어든다. patch와 마찬가지로 이를 반복하여(논문에서는 4단계를 사용해서 8x8, 4x4, 2x2, 1x1로 처리됨) masking처리를 한다.
Hiera의 아키텍쳐와 MViTv2에 대한 더 자세한 개선 사항은 참고의 논문 페이지 참조.
Sample Code
Hiera의 코드는 git hub에 공개되므로 Hiera 클래스를 포함한 전체 코드는 아래 링크 참조
Hiera는 MVitv2의 pooling attention을 아래의 Mask Unit Attention으로 대체한다.
class MaskUnitAttention(nn.Module):
def __init__(
self,
dim: int,
dim_out: int,
heads: int,
q_stride: int = 1,
window_size: int = 0,
use_mask_unit_attn: bool = False,
):
super().__init__()
self.dim = dim
self.dim_out = dim_out
self.heads = heads
self.q_stride = q_stride
self.head_dim = dim_out // heads
self.scale = (self.head_dim) ** -0.5
self.qkv = nn.Linear(dim, 3 * dim_out)
self.proj = nn.Linear(dim_out, dim_out)
self.window_size = window_size
self.use_mask_unit_attn = use_mask_unit_attn
def forward(self, x: torch.Tensor) -> torch.Tensor:
B, N, _ = x.shape
num_windows = (
(N // (self.q_stride * self.window_size)) if self.use_mask_unit_attn else 1
)
qkv = (
self.qkv(x)
.reshape(B, -1, num_windows, 3, self.heads, self.head_dim)
.permute(3, 0, 4, 2, 1, 5)
)
q, k, v = qkv[0], qkv[1], qkv[2]
if self.q_stride > 1:
# Refer to Unroll to see how this performs a maxpool-Nd
q = (
q.view(B, self.heads, num_windows, self.q_stride, -1, self.head_dim)
.max(dim=3)
.values
)
if hasattr(F, "scaled_dot_product_attention"):
# Note: the original paper did *not* use SDPA, it's a free boost!
x = F.scaled_dot_product_attention(q, k, v)
else:
attn = (q * self.scale) @ k.transpose(-1, -2)
attn = attn.softmax(dim=-1)
x = (attn @ v)
x = x.transpose(1, 3).reshape(B, -1, self.dim_out)
x = self.proj(x)
return x
Python
복사
