
Segment Anything(SAM)
Segment Anything(SAM)은 Computer Vision의 Foundation model을 목표로 만들어진 모델로, 저자들은 각종 vision task로 transfer 가능한 task로 segmentation이 적합하다고 판단해서, SAM을 segmentation을 수행하는 모델을 만들었음. 또한 최근 경향을 반영하여 다양한 downstream task를 잘 적용될 수 있도록 prompting이 가능하도록 모델을 구성하여 최종적으로 SAM은 promptable segmentation task를 수행하는 모델이 되었음.
일반화된 Foundation Model이기 때문에 특정 downstream task(edge detection, object proposal, instance segmentation, text to mask 등)에 대해 fine-tuning 하지 않으면 해당 task에 특화된 모델만큼의 성능은 나오지 않지만, 해당 task에 대한 학습 없이 zero-shot transfer (prompt 엔지니어링)만으로도 저자들은 합리적인 수준의 결과물이 나올 수 있다고 한다.
Architecture
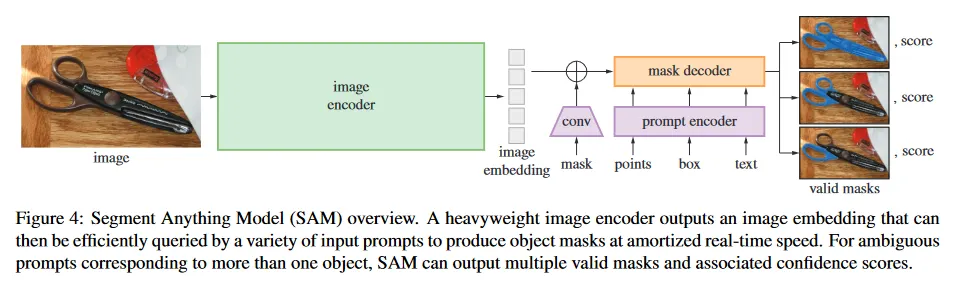
SAM은 크게 Image Encoder, Prompt Encoder, Mask Decoder라는 3가지 컴포넌트로 구성된다.
여기서 Image Encoder는 image embedding을 출력하는 임의의 네트워크일 수 있지만, SAM에서는 ViT로 pre-train 된 MAE(Masked Autoencoder)를 사용하였음. 고해상도 입력을 처리하기 위해 최소한의 수정된 MAE를 사용하지만, 해당 모델을 freeze하지 않고 역전파 시켜 파라미터를 업데이트 한다.
Prompt Encoder는 Image Encoder와 Mask Decoder와 달리 자체적으로 정의한 구조를 사용한다. Prompt Encoder는 mask, points, box, text를 입력으로 받는데, point, box, text는 사용자가 UI를 통해 입력하는 정보이지만, mask는 사용자가 직접 입력하는 것이 아니라 이전 단계의 mask 출력(이것은 학습 하는 동안 iteration을 반복하거나 추론시에 예측된 결과를 바탕으로 사용자가 추가 prompt를 입력하는 경우에 발생할 수 있다)을 사용한다. prompt text는 pre-trained CLIP 모델을 이용하여 embedding을 수행하므로 역전파 대상이 아닌 반면, mask, point, box는 각각 별도의 embedding layer을 사용하므로 역전파 대상이다. 추가로 mask는 dense embedding으로, point, box, text는 sparse embedding으로 처리한다.
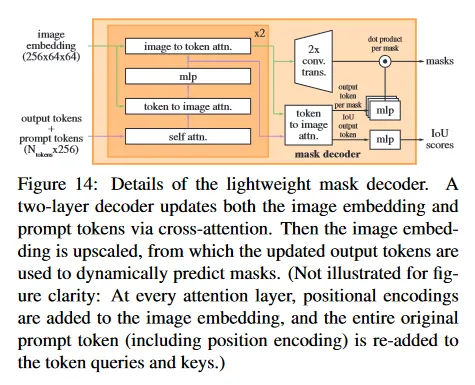
Mask Decoder는 Transformer Decoder를 사용하며 구성되고, Image Encoder의 image embedding과 Prompt Encoder의 Dense, Sparse Embedding을 입력으로 받아 최종적으로 Mask를 출력한다. 여기서 Mask Token과 IoU Token을 사용하여 Mask에 대한 예측과 해당 Mask의 품질(IoU Score)를 출력한다.
Mask Token의 경우 기본적으로 (whole, part, subpart)를 예측하는 3개의 token을 갖지만, prompt가 multiple일 경우 단일 mask만 예측하는 4번째 토큰을 사용한다. 다시 말해 prompt가 단일일 때는 whole, part, subpart에 대한 3개의 mask가 출력되지만, multiple일 경우 4번째 토큰만 사용하여 단일 mask를 출력한다. 이것은 단일 prompt에서 발생할 수 있는 모호성 문제를 해결하고, multiple prompt에서는 결합된 정보를 바탕으로 단일 mask만 출력하기 위한 용도이다.
SAM의 loss 함수는 focal loss와 dice loss를 20:1로 합하여 사용한다.
SAM의 아키텍쳐에 대한 더 상세한 내용은 참고의 논문 페이지 참조.
Training
SAM은 모델을 학습 하기 위해 Interactive Sampling 방법을 사용한다. 이것은 처음에 임의의 초기 prompt(point or bounding box)를 샘플링한 다음, noise를 추가하여 모델에 입력하고 mask를 예측한다. 이 mask는 ground truth mask와 비교하여 오류 영역을 설정하고, 해당 영역에서 다시 새로운 prompt를 샘플링하고 이전의 예측된 mask를 추가 prompt로 모델에 입력하여 다시 mask를 예측하고 전체 절차를 반복한다.
저자들은 위의 절차를 8번 반복하고, 외부 prompt 없이 이전 mask 예측을 기반으로 mask 예측을 수정하도록 하는 2번의 절차를 반복하여 첫 샘플링과 합해 총 11번의 반복을 수행한다.
학습 알고리즘에 대한 상세한 절차는 참고의 논문 부록 페이지 참조
Sample Code
공식 git에 올라와 있는 SAM 코드만 정리. ImageEncoder는 ViT를 사용하고, MaskDecoder는 nn.Module로 구현된 Transformer를 사용한다. PromptEncoder는 직접 정의한 구조를 사용.
더 자세한 코드는 공식 코드 참조.
class Sam(nn.Module):
mask_threshold: float = 0.0
image_format: str = "RGB"
def __init__(
self,
image_encoder: ImageEncoderViT,
prompt_encoder: PromptEncoder,
mask_decoder: MaskDecoder,
pixel_mean: List[float] = [123.675, 116.28, 103.53],
pixel_std: List[float] = [58.395, 57.12, 57.375],
) -> None:
super().__init__()
self.image_encoder = image_encoder
self.prompt_encoder = prompt_encoder
self.mask_decoder = mask_decoder
self.register_buffer("pixel_mean", torch.Tensor(pixel_mean).view(-1, 1, 1), False)
self.register_buffer("pixel_std", torch.Tensor(pixel_std).view(-1, 1, 1), False)
@property
def device(self) -> Any:
return self.pixel_mean.device
@torch.no_grad()
def forward(
self,
batched_input: List[Dict[str, Any]],
multimask_output: bool,
) -> List[Dict[str, torch.Tensor]]:
input_images = torch.stack([self.preprocess(x["image"]) for x in batched_input], dim=0)
image_embeddings = self.image_encoder(input_images)
outputs = []
for image_record, curr_embedding in zip(batched_input, image_embeddings):
if "point_coords" in image_record:
points = (image_record["point_coords"], image_record["point_labels"])
else:
points = None
sparse_embeddings, dense_embeddings = self.prompt_encoder(
points=points,
boxes=image_record.get("boxes", None),
masks=image_record.get("mask_inputs", None),
)
low_res_masks, iou_predictions = self.mask_decoder(
image_embeddings=curr_embedding.unsqueeze(0),
image_pe=self.prompt_encoder.get_dense_pe(),
sparse_prompt_embeddings=sparse_embeddings,
dense_prompt_embeddings=dense_embeddings,
multimask_output=multimask_output,
)
masks = self.postprocess_masks(
low_res_masks,
input_size=image_record["image"].shape[-2:],
original_size=image_record["original_size"],
)
masks = masks > self.mask_threshold
outputs.append(
{
"masks": masks,
"iou_predictions": iou_predictions,
"low_res_logits": low_res_masks,
}
)
return outputs
def postprocess_masks(
self,
masks: torch.Tensor,
input_size: Tuple[int, ...],
original_size: Tuple[int, ...],
) -> torch.Tensor:
masks = F.interpolate(
masks,
(self.image_encoder.img_size, self.image_encoder.img_size),
mode="bilinear",
align_corners=False,
)
masks = masks[..., : input_size[0], : input_size[1]]
masks = F.interpolate(masks, original_size, mode="bilinear", align_corners=False)
return masks
def preprocess(self, x: torch.Tensor) -> torch.Tensor:
# Normalize colors
x = (x - self.pixel_mean) / self.pixel_std
# Pad
h, w = x.shape[-2:]
padh = self.image_encoder.img_size - h
padw = self.image_encoder.img_size - w
x = F.pad(x, (0, padw, 0, padh))
return x
Python
복사
Data Engine
LLM과 같은 Foundation 모델이 Web에서 수집한 대규모 데이터를 사용할 수 있는 반면, Segmentation에 대해서는 대규모 데이터를 사용할 수 없기 때문에 저자들은 SAM의 데이터셋을 구축하기 위해 데이터 수집 및 생성을 자동화하는 파이프라인인 Data Engine을 구축해서 segmentation dataset을 구축했다. (Data Engine은 라벨링 데이터를 이용해서 SAM 모델을 학습시키고, 학습된 모델을 이용해서 segmentation mask를 생성하는 프로그램이다)
segmentation 비용이 비싸기 때문에 총 3단계로 Data Engine을 구축했는데, 1단계에서는 전문 주석작업자들이 라벨링을 수행하면, SAM의 Data Engine을 우선 공개된 segmentation 데이터를 이용해서 학습하는 한편, 라벨링 데이터셋이 충분히 확보되면 추가된 라벨링 데이터셋을 이용해서 Data Engine을 재학습한다.
두 번째 단계에서는 반자동으로 우선 Data Engine을 이용해서 segmentation mask를 생서한 후에 전문 주석 작업자들이 추가적으로 주석처리하고, 추가된 주석 데이터로 Data Engine을 학습한다.
마지막 세 번째 단계에서는 완전 자동으로 Data Engine에서 mask를 생성하고, 모호성 인식 모델을 개발해서 모호한 경우에서도 유효한 mask를 생성하도록 하고 중복 처리를 수행한다.
Sample Code
SAM을 이용해서 mask를 생성하는 샘플 코드. 더 자세한 내용은 공식 git 참조
class SamAutomaticMaskGenerator:
def __init__(
self,
model: Sam,
points_per_side: Optional[int] = 32,
points_per_batch: int = 64,
pred_iou_thresh: float = 0.88,
stability_score_thresh: float = 0.95,
stability_score_offset: float = 1.0,
box_nms_thresh: float = 0.7,
crop_n_layers: int = 0,
crop_nms_thresh: float = 0.7,
crop_overlap_ratio: float = 512 / 1500,
crop_n_points_downscale_factor: int = 1,
point_grids: Optional[List[np.ndarray]] = None,
min_mask_region_area: int = 0,
output_mode: str = "binary_mask",
) -> None:
assert (points_per_side is None) != (
point_grids is None
), "Exactly one of points_per_side or point_grid must be provided."
if points_per_side is not None:
self.point_grids = build_all_layer_point_grids(
points_per_side,
crop_n_layers,
crop_n_points_downscale_factor,
)
elif point_grids is not None:
self.point_grids = point_grids
else:
raise ValueError("Can't have both points_per_side and point_grid be None.")
assert output_mode in [
"binary_mask",
"uncompressed_rle",
"coco_rle",
], f"Unknown output_mode {output_mode}."
if output_mode == "coco_rle":
from pycocotools import mask as mask_utils # type: ignore # noqa: F401
if min_mask_region_area > 0:
import cv2 # type: ignore # noqa: F401
self.predictor = SamPredictor(model)
self.points_per_batch = points_per_batch
self.pred_iou_thresh = pred_iou_thresh
self.stability_score_thresh = stability_score_thresh
self.stability_score_offset = stability_score_offset
self.box_nms_thresh = box_nms_thresh
self.crop_n_layers = crop_n_layers
self.crop_nms_thresh = crop_nms_thresh
self.crop_overlap_ratio = crop_overlap_ratio
self.crop_n_points_downscale_factor = crop_n_points_downscale_factor
self.min_mask_region_area = min_mask_region_area
self.output_mode = output_mode
@torch.no_grad()
def generate(self, image: np.ndarray) -> List[Dict[str, Any]]:
# Generate masks
mask_data = self._generate_masks(image)
# Filter small disconnected regions and holes in masks
if self.min_mask_region_area > 0:
mask_data = self.postprocess_small_regions(
mask_data,
self.min_mask_region_area,
max(self.box_nms_thresh, self.crop_nms_thresh),
)
# Encode masks
if self.output_mode == "coco_rle":
mask_data["segmentations"] = [coco_encode_rle(rle) for rle in mask_data["rles"]]
elif self.output_mode == "binary_mask":
mask_data["segmentations"] = [rle_to_mask(rle) for rle in mask_data["rles"]]
else:
mask_data["segmentations"] = mask_data["rles"]
# Write mask records
curr_anns = []
for idx in range(len(mask_data["segmentations"])):
ann = {
"segmentation": mask_data["segmentations"][idx],
"area": area_from_rle(mask_data["rles"][idx]),
"bbox": box_xyxy_to_xywh(mask_data["boxes"][idx]).tolist(),
"predicted_iou": mask_data["iou_preds"][idx].item(),
"point_coords": [mask_data["points"][idx].tolist()],
"stability_score": mask_data["stability_score"][idx].item(),
"crop_box": box_xyxy_to_xywh(mask_data["crop_boxes"][idx]).tolist(),
}
curr_anns.append(ann)
return curr_anns
Python
복사
