
V-JEPA
V-JEPA는 masking을 이용하여 self-supervised learning 하는 모델인 I-JEPA를 video 데이터에 맞게 확장한 모델이다. 따라서 V-JEPA를 이해하려면 I-JEPA를 먼저 이해하는 편이 낫다. V-JEPA는 이미지를 비디오로 확장한 것에서 발생하는 몇 가지 변경을 제외하고는 I-JEPA와 상당히 유사하므로 I-JEPA를 이해했다면 V-JEPA는 쉽게 이해할 수 있다(따라서 여기서도 자세한 내용은 생략. 참조의 I-JEPA 페이지 참조).
이것은 I-JEPA에서처럼 2개의 네트워크(-encoder, -encoder)와 predictor를 갖고, 모두 ViT 아키텍쳐를 기반으로 한다. 다만 predictor는 예측만 수행하므로 narrow한 transformer block을 사용한다.
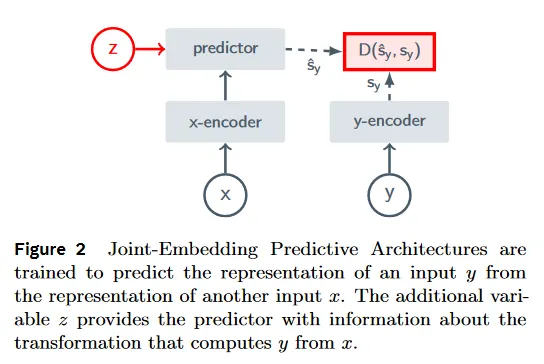
학습시 I-JEPA와 유사하게 동일한 원본에 대해 masking 된 영역을 제거한 전체 데이터를 -encoder에 넣고, 전체가 아니라 masking 데이터를 -encoder에 넣어 각각 encoding한 후에, predictor가 (잠재 변수 를 조건으로) -encoder의 출력에 대해 masking 된 부분을 예측한다. predictor의 예측은 pixel 공간이 아닌 latent space(논문에서 feature level이라 부름)에서 수행되는 것이 특징이며, 계산된 loss()는 predictor와 -encoder에만 역전파하고, -encoder는 exponential moving average(EMA)를 통해 -encoder의 파라미터를 업데이트 받는다.
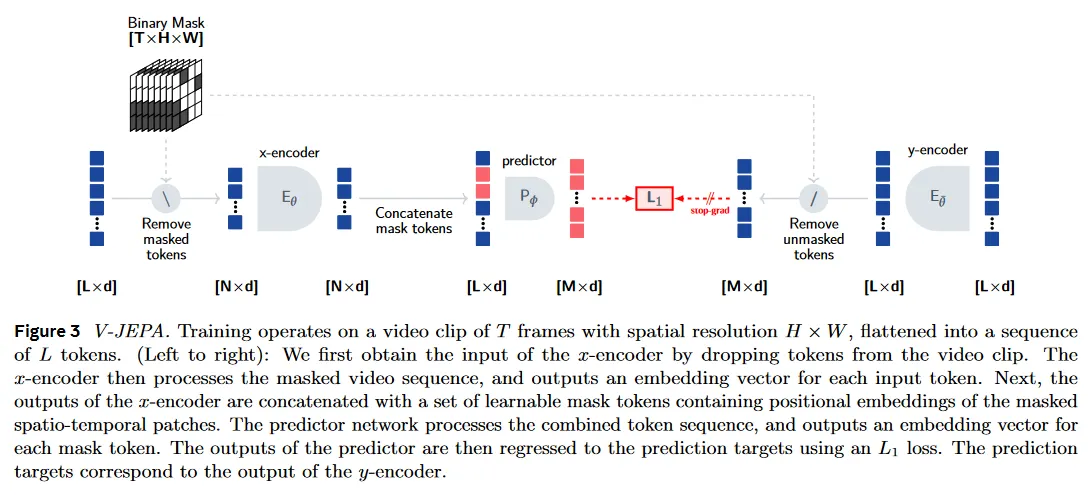
V-JEPA는 비디오 데이터를 다루기 때문에 I-JEPA와 달리 patch를 2개의 프레임에 걸친 3D grid로 구성하여 공간적 패턴 뿐만 아니라 시간적 패턴도 학습할 수 있도록 한다. 또한 I-JEPA와 달리 V-JEPA는 short-range mask와 long-range mask라는 2가지 masking 전략을 사용하는데, 여기서 short-range mask은 프레임의 15%를 차지하고 long-range mask라는 와 프레임의 70%를 차지하는 mask를 말한다. V-JEPA에서는 이러한 masking 전략을 multi-block이라 부른다.
V-JEPA의 더 자세한 내용과 실험 결과는 참고의 논문 페이지 참조.
기본 아키텍쳐가 유사하므로 sample code는 아래의 공식 git의 코드나 참고의 I-JEPA 페이지의 sample code 참조.
